#
Web Rapid Typing
(1)题目描述
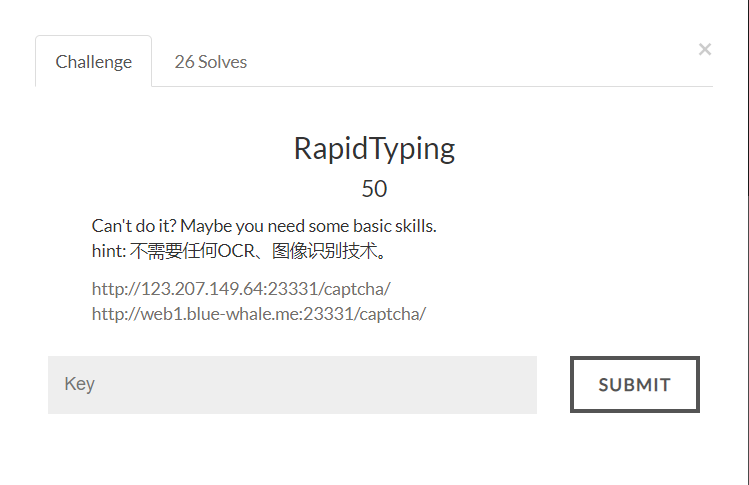
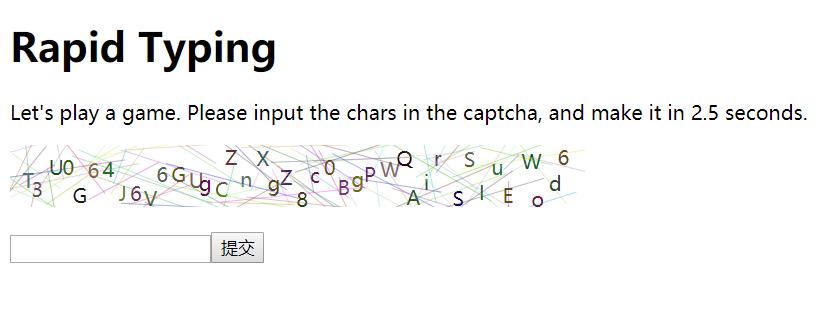
- 从题目描述来看,和Calculator性质类似,需要快速获取网页内容,经过处理后返回结果
import requests
url_1 = ‘http://web1.blue-whale.me:23331/captcha/’
url_2 = ‘http://web1.blue-whale.me:23331/captcha/?code=’
session = requests.session()
r = session.get(url)
html = r.text
(2)问题分析
- 打开网页源代码后,发现验证码在标签内部,而且验证码是经过base64编码的,因此需要使用base64库进行解码。
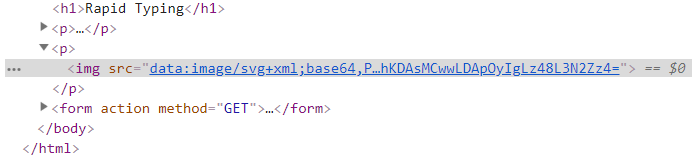
-
将验证码的图片下载到本地,发现是svg格式,google以后发现,用户可以直接用代码来描绘图像,可以用任何文字处理工具打开SVG图像,通过改变部分代码来使图像具有交互功能,并可以随时插入到HTML中通过浏览器来观看。
-
使用记事本打开svg图片,发现text里面有不同的x,y值,猜测应该是验证码的横、纵坐标,所以最后将验证码返回结果时,应该按照x坐标来进行排序
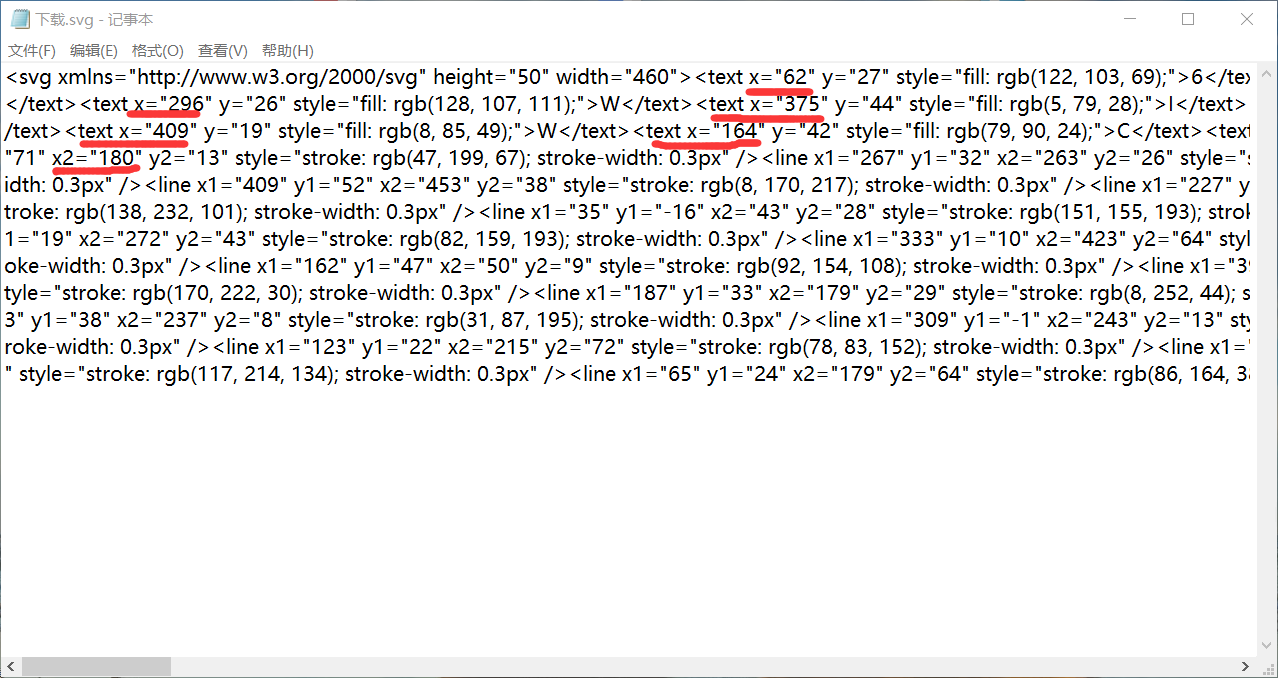
- google后得知可以使用BeautifulSoup来从xml中提取数据
(3)解题
- 与URL建立连接
session = requests.session()
r = session.get('http://123.207.149.64:23331/captcha/')
r.encoding = "utf-8"
- 使用BeautifulSoup获取SVG源码
BS = BeautifulSoup(r.text, "html.parser")
img_0 = BS.find_all(name="img")
for each in img_0:
svg = each.get('src')
svg = svg.split(",")[-1]
- base64解码
svg_0 = base64.b64decode(svg)
BS = BeautifulSoup(svg_0, "html.parser")
text_0 = BS.find_all(name="text")
- 将解码后得到的字符按x排序
line_1 = sorted(text_0, key=lambda x: int(x.get("x")))
x = ""
for each in line_1:
x += each.string
- 得到flag
